Experimental Plots
Publication-quality figures generated at 300 DPI. Click any image to expand.
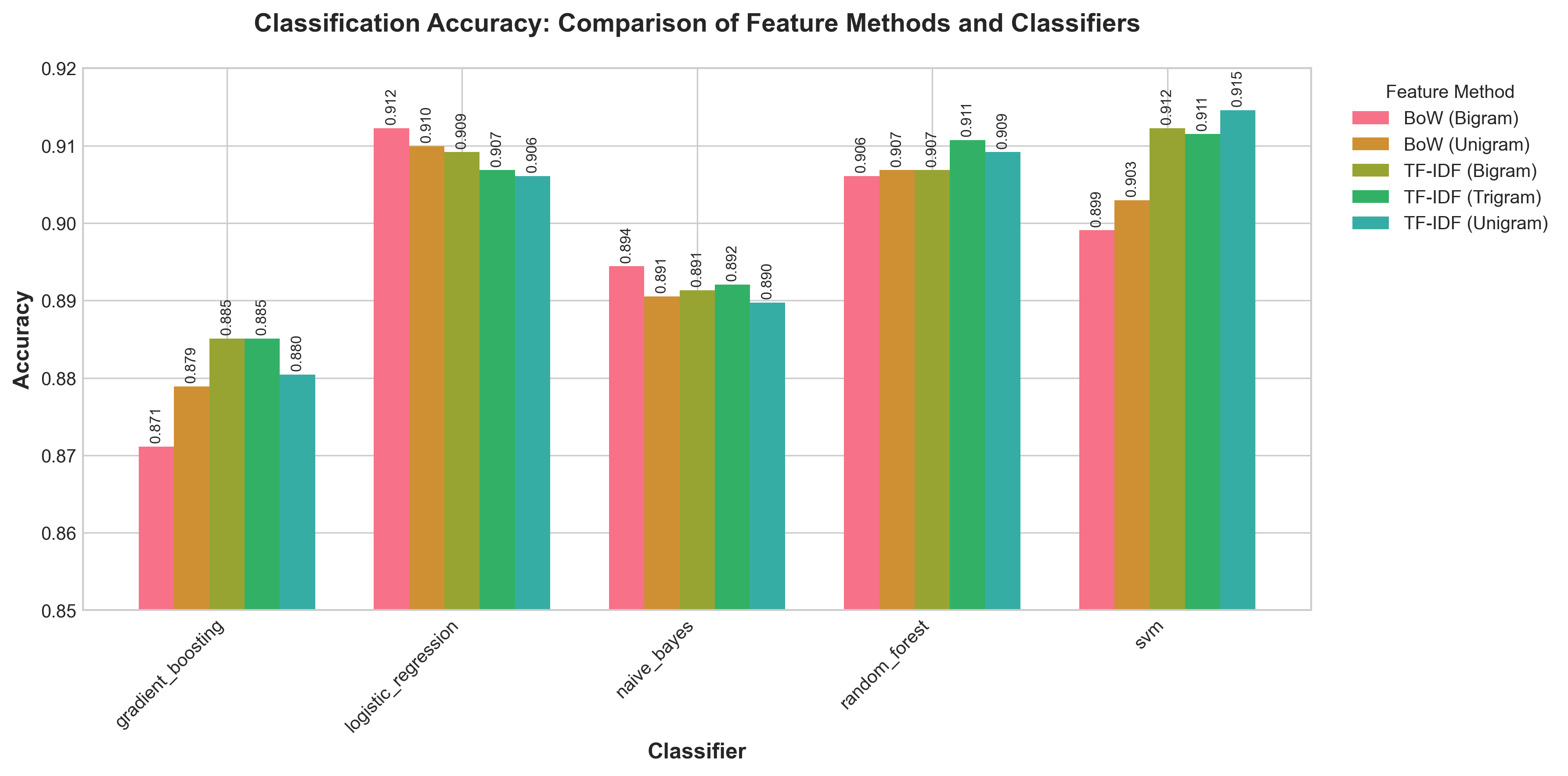
Accuracy Comparison
Grouped bar chart of classification accuracy across all feature methods and classifiers, with values annotated on each bar.
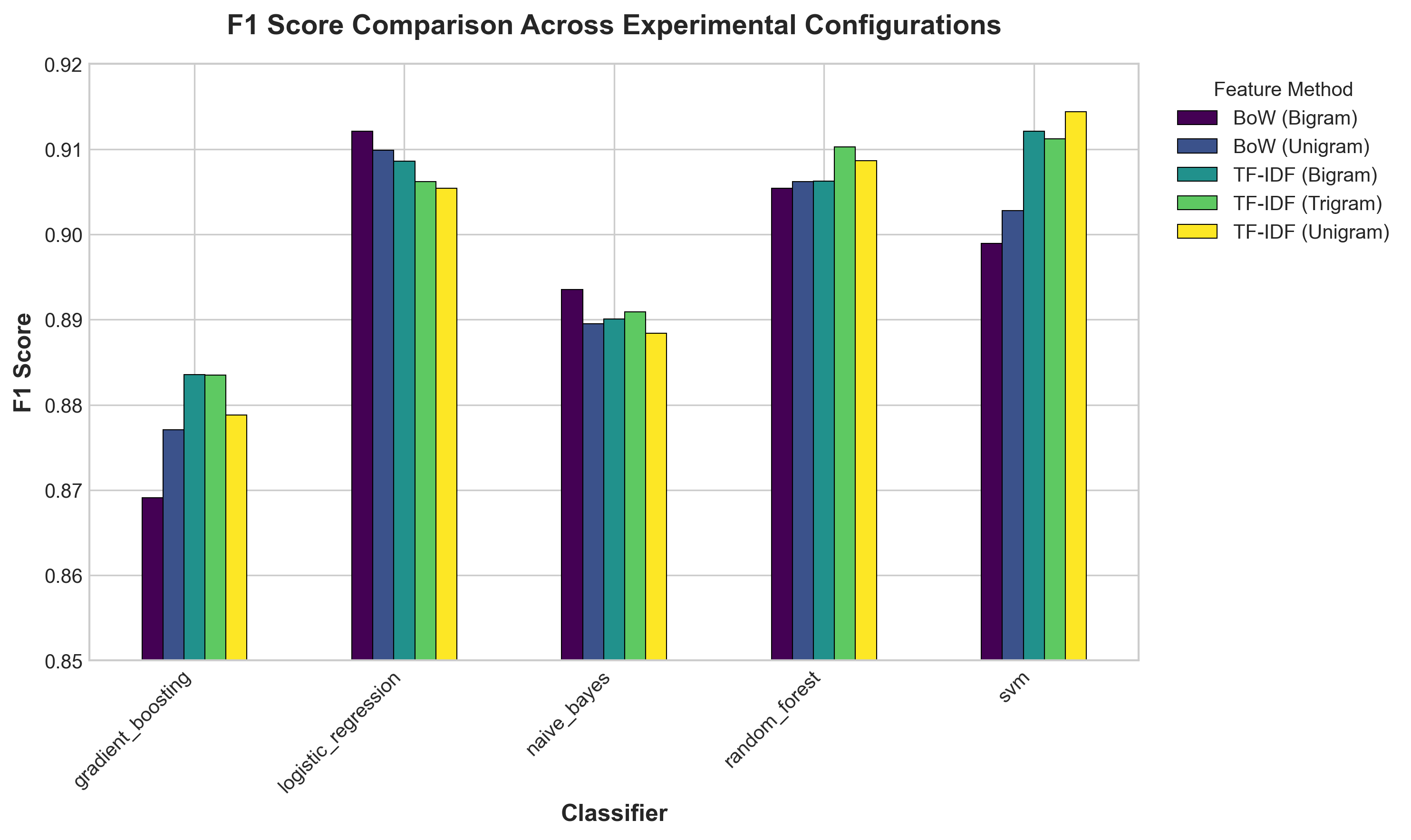
F1-Score Comparison
Weighted F1-score across all 25 experimental configurations.
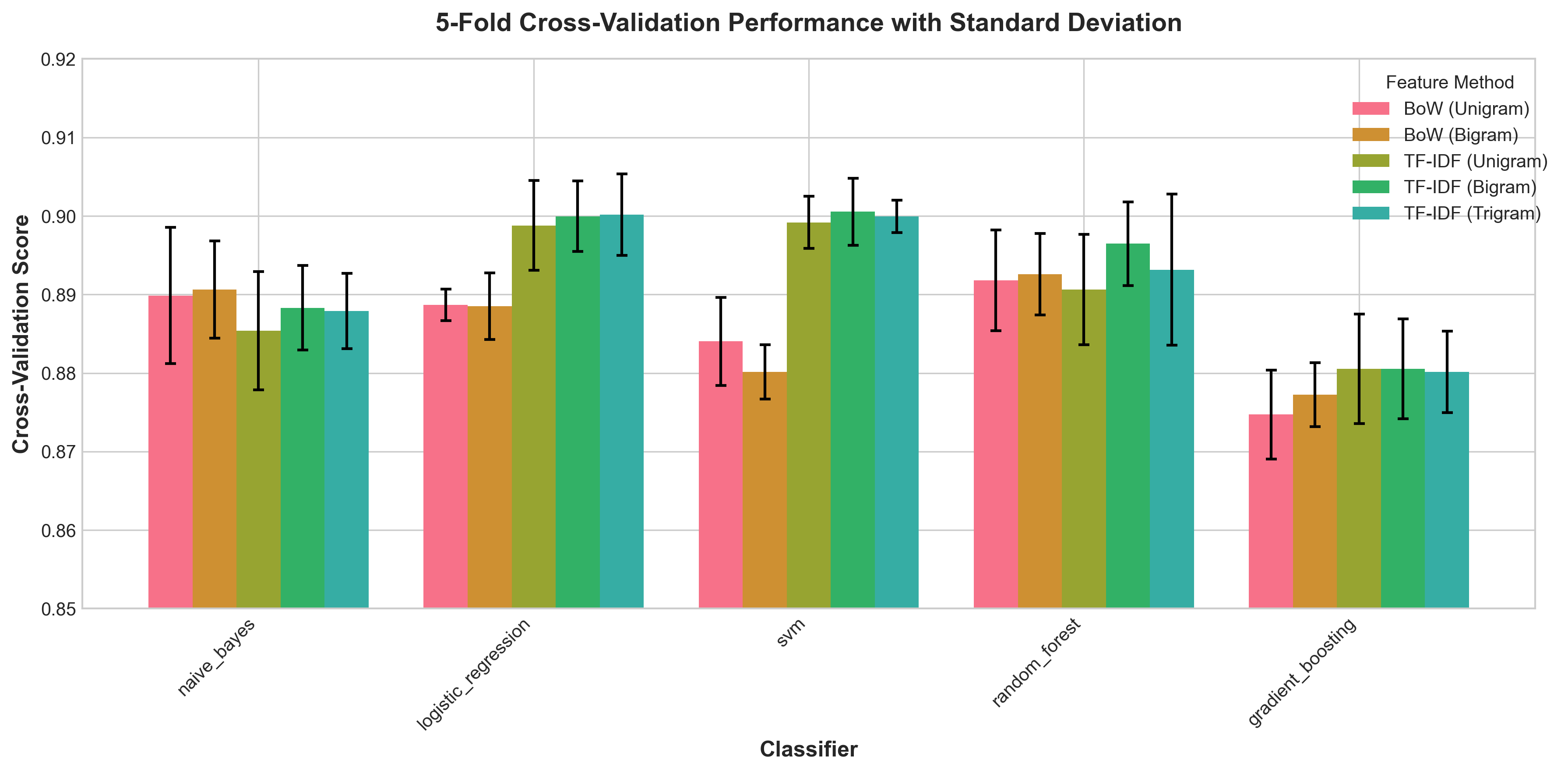
Cross-Validation Scores
5-fold CV performance with standard deviation error bars showing stability.
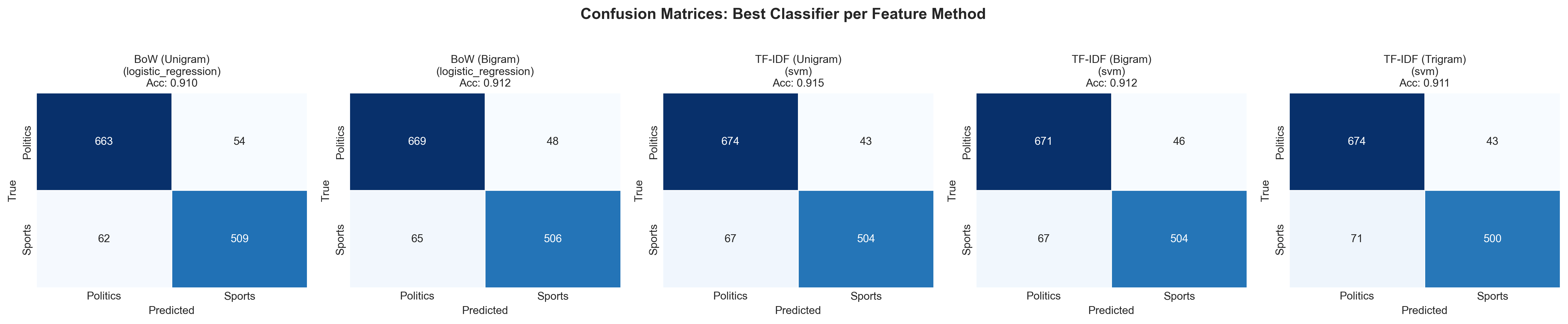
Confusion Matrices
Best classifier per feature method. Note the asymmetry: sports articles misclassified as politics more often than the reverse.
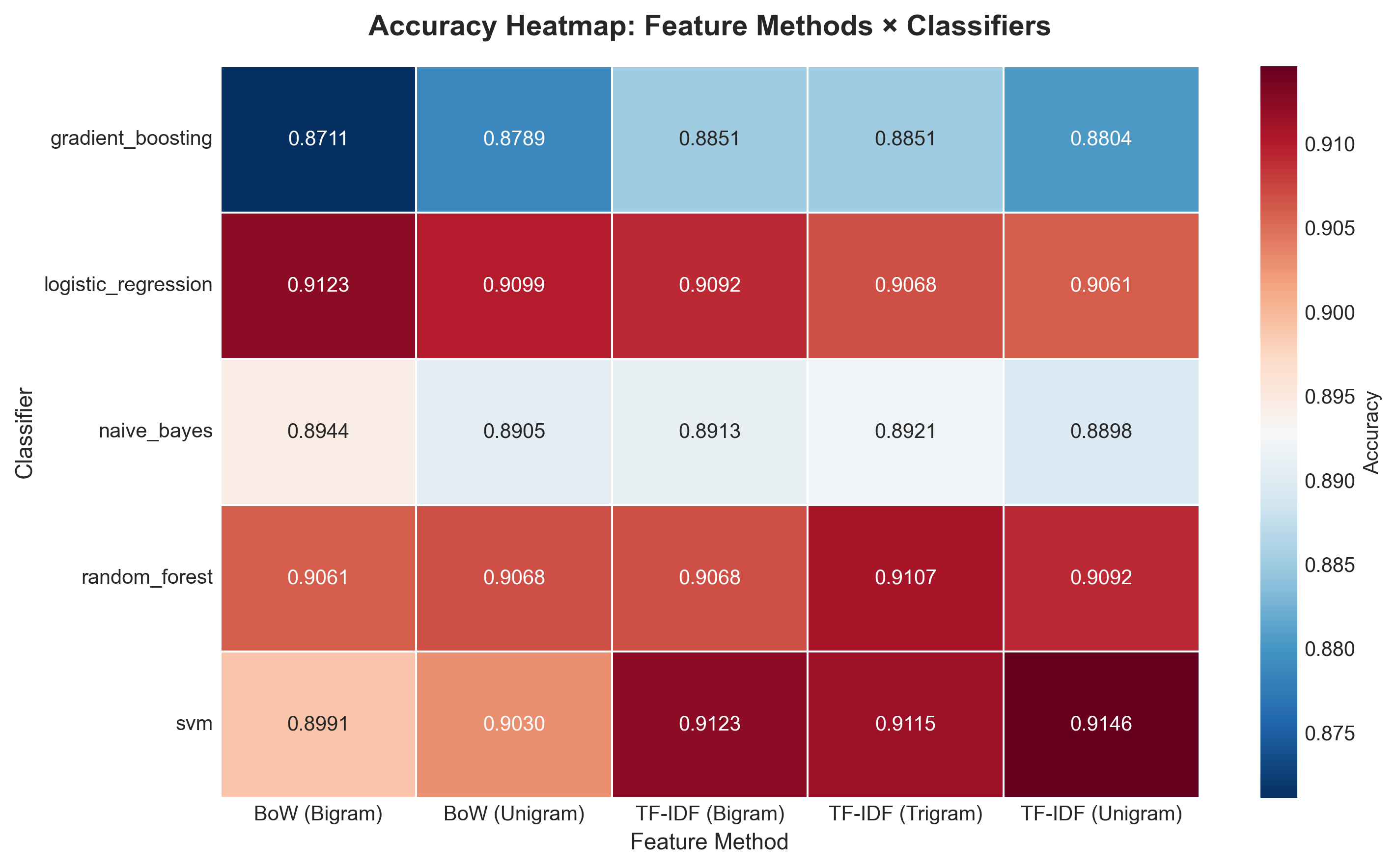
Accuracy Heatmap
Feature methods × classifiers grid. Darker red = higher accuracy.
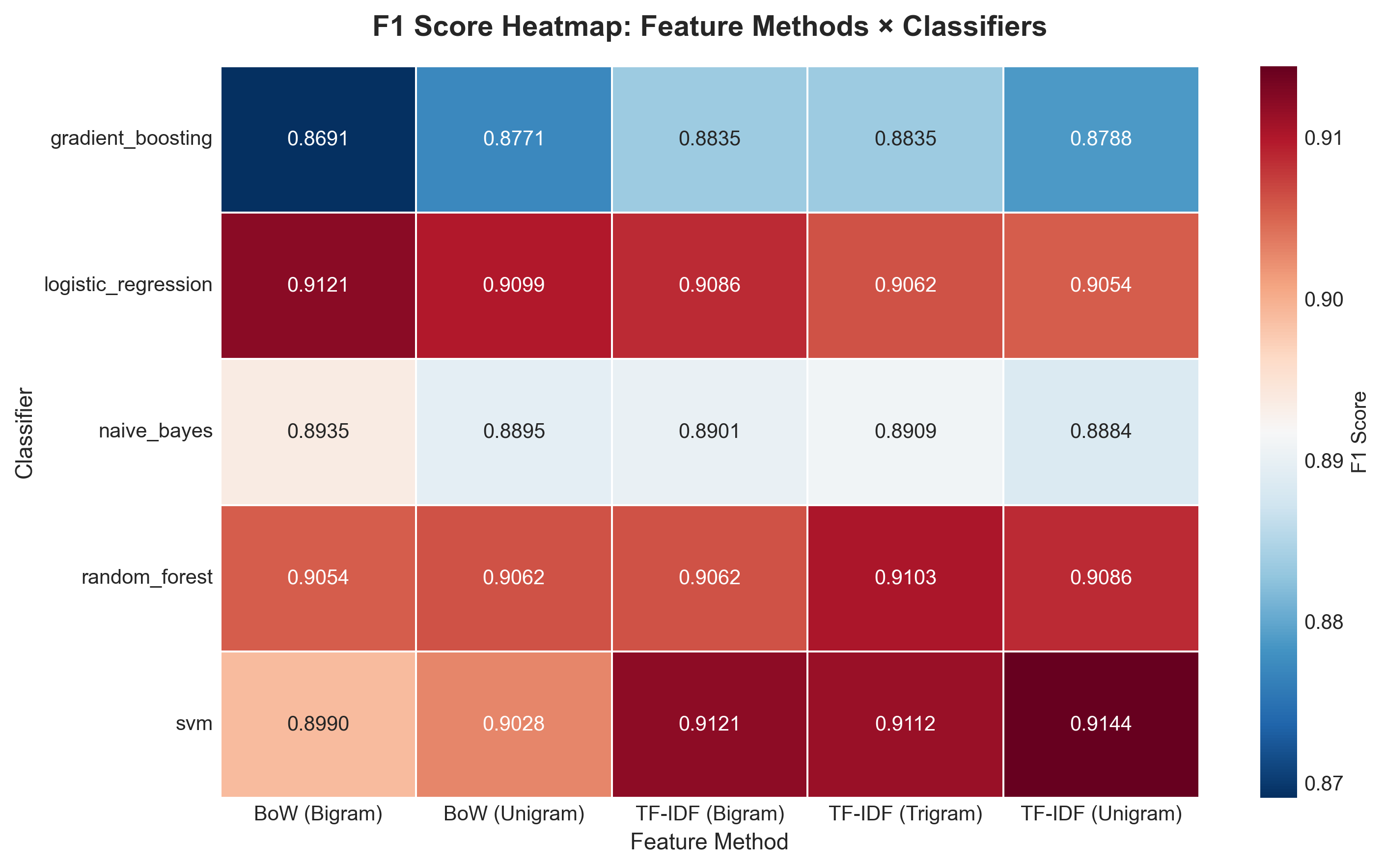
F1-Score Heatmap
Weighted F1 heatmap mirroring the accuracy pattern closely.
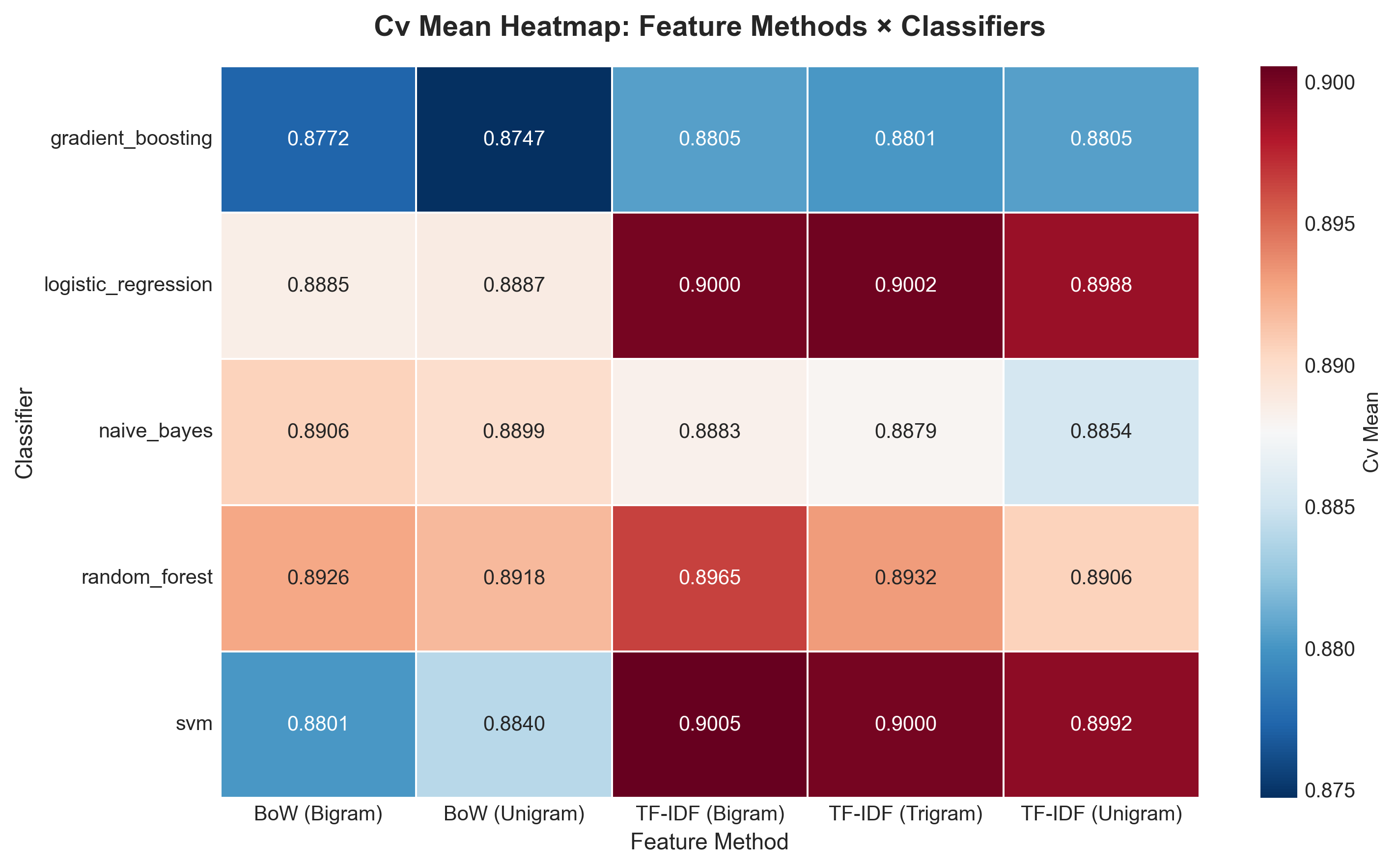
CV Mean Heatmap
Cross-validation mean accuracy. TF-IDF features dominate the warm end.
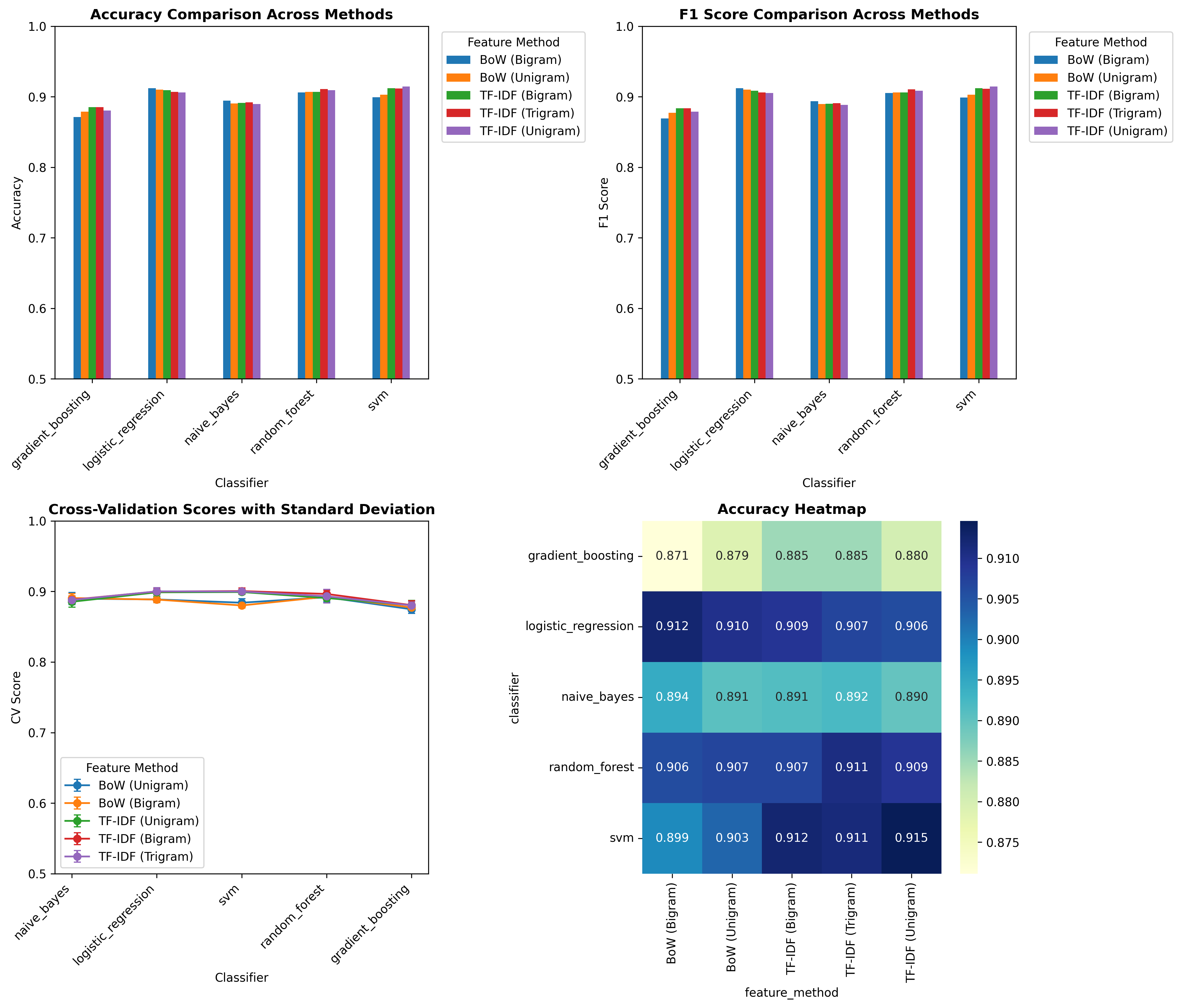
Multi-Panel Summary
Four-panel overview: accuracy, F1, CV scores, and heatmap in one figure.
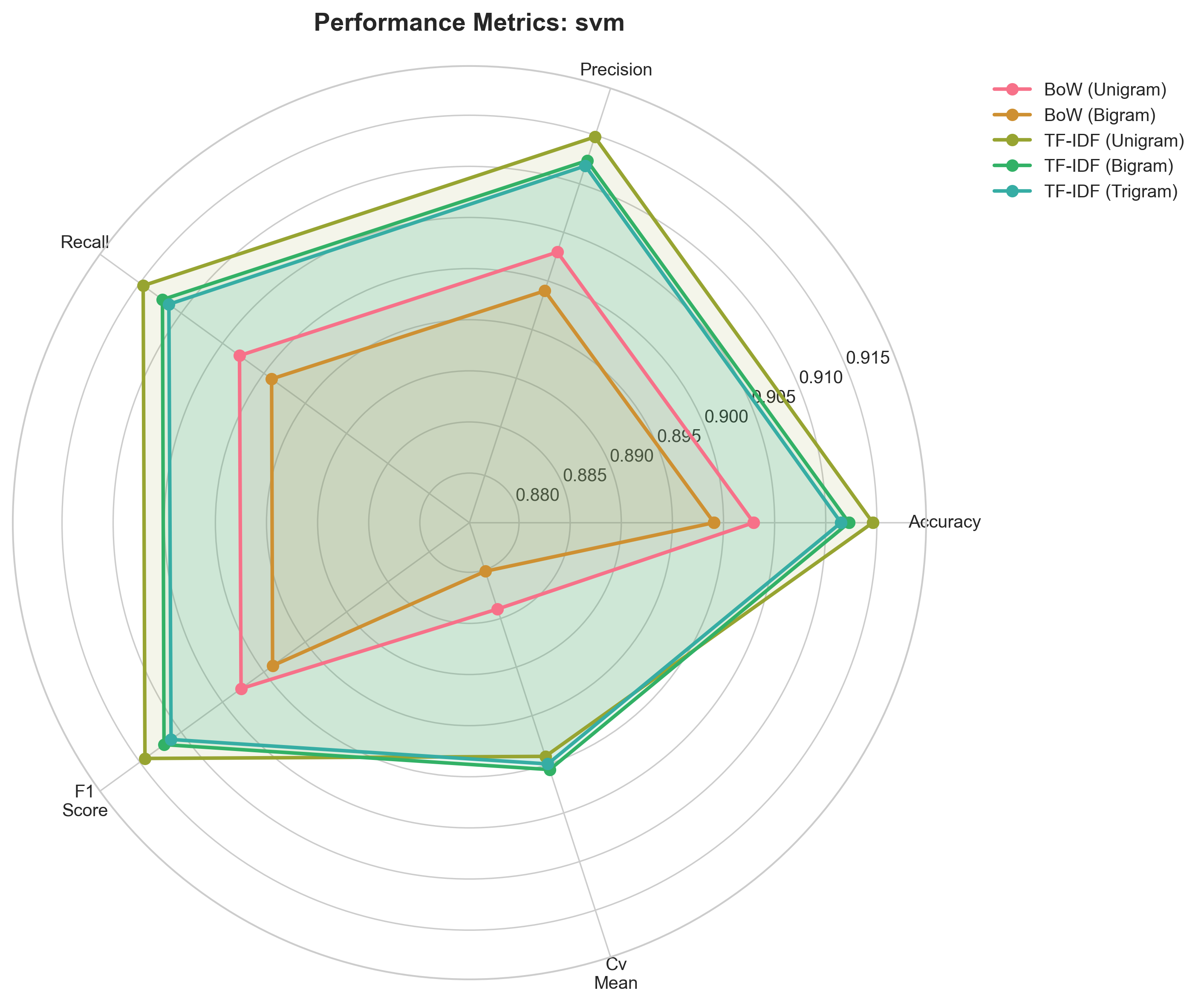
Radar Chart — SVM
Multi-metric profile. TF-IDF features push the polygon outward on all axes.
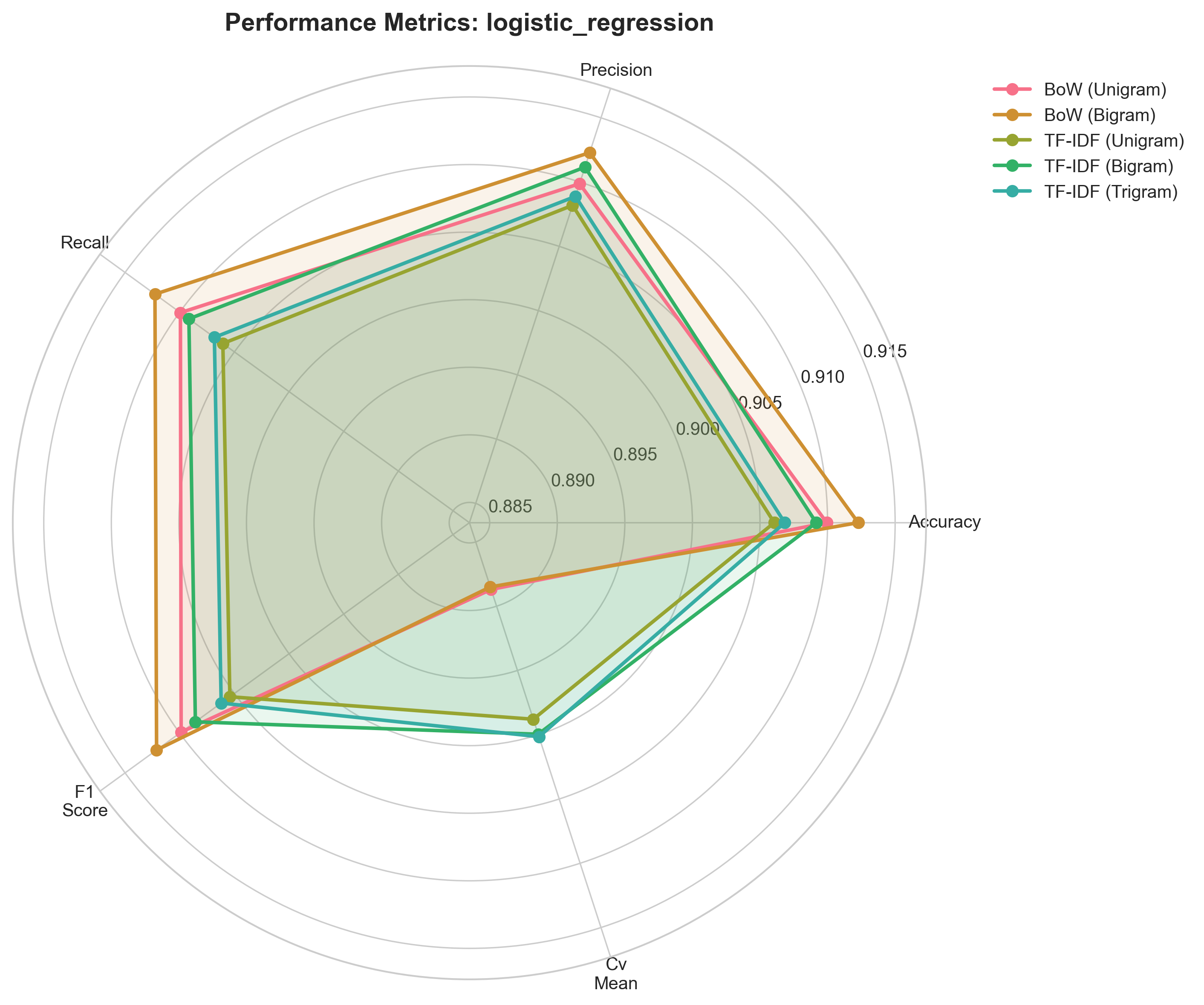
Radar Chart — Logistic Regression
BoW (Bigram) dominates here, unlike SVM where TF-IDF leads.
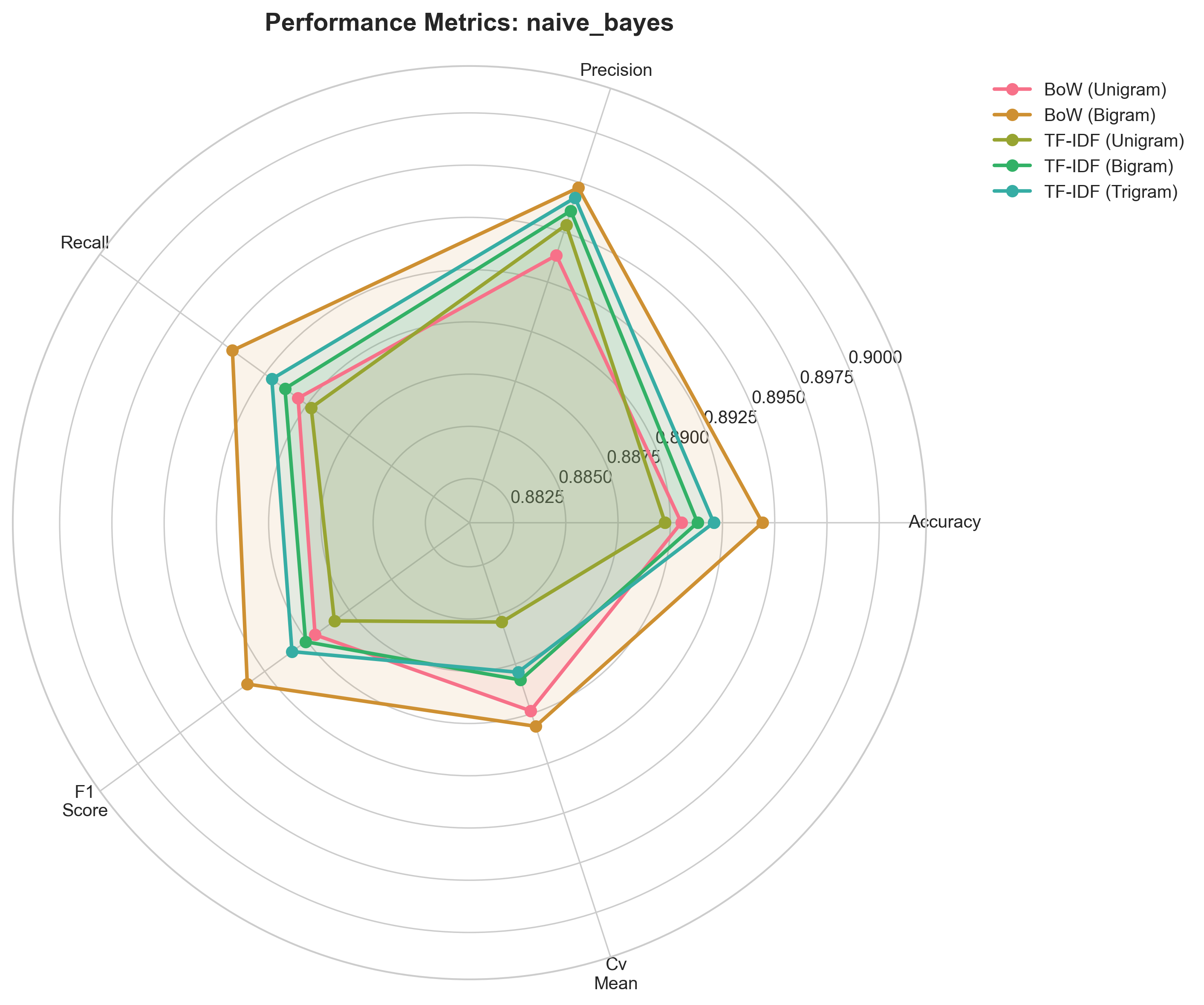
Radar Chart — Naive Bayes
Most compact polygon among the three, reflecting lower overall scores.